
A TiDAR (Think in Diffusion, Talk in Autoregression) elnevezésű tanulmány egy rendhagyó nyelvi modellezési technikai megoldást mutat be, amely a GPU-k kihasználatlan kapacitásának okos hasznosításával foglalkozik nagy nyelvi modellek inferenciája során.
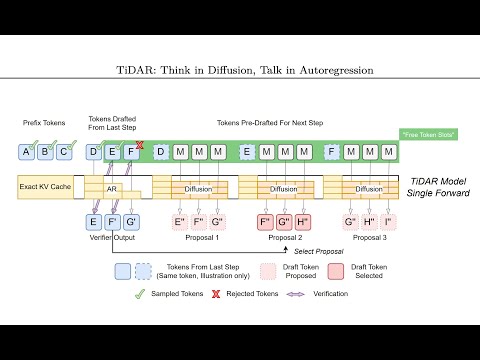
A szerzők rámutatnak, hogy az autoregresszív, sorról sorra építkező szöveggenerálás időigényes lehet, mert főként a memóriakezelésen bukik el a GPU teljes kihasználása. Felmerül az a kérdés, miként lehetne párhuzamosan előkészíteni több választási lehetőséget úgy, hogy az ne járjon jelentős kompromisszumokkal, mint például a spekulatív dekódolásnál.
A címben is megnevezett két alapvető modell, az autoregresszív és a diffúziós nyelvi modellek koncepcióját ütköztetik. Az autoregresszív modellek jobb minőséget, míg a diffúziós megközelítések gyorsabb működést ígérnek. A fő dilemma: hogyan lehet ötvözni a két irány erényeit anélkül, hogy a teljesítményt feláldoznánk a gyorsaság oltárán.
A tanulmány betekintést ad abba, hogy miként lehet reális javaslatokat generálni a következő tokenekre vonatkozóan, akár diffúziós modellek segítségével, melyeket aztán egy autoregresszív modell ellenőrizhet. Kiemelt szerephez jut a spekulatív dekódolás mechanizmusa és annak továbbfejlesztése.
Részletesen elemzik a maszkos figyelmi eljárásokat, a prefixumok, javasolt tokenek és a gyors draftok kezelésének eljárásait. Ügyes figyelemmaszkolási trükkök révén egyidejűleg több lehetséges jövőbeli mintát párhuzamosan lehet generálni és ellenőrizni, miközben fontos kérdéseket vetnek fel a diffúziós és autoregresszív veszteségek összegzésének, illetve a tanulási stratégiáknak a hatékonyságáról.









