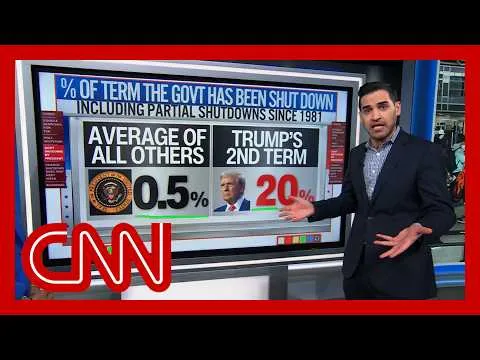
Mit jelent pontosan, hogy egy kereső szisztematikusan feltérképezi az internetet? A beszélgetés során a vendégek felvázolják azokat a történelmi és technológiai alapokat, amelyek nélkül ma nem létezhetnének modern keresőmotorok.
Szó esik arról, hogyan működnek az internetes robotok – más néven crawlerek –, hogyan fejlődtek az évek során, és milyen kihívásokkal kell napjainkban szembenézniük, például a sávszélesség hatékony kihasználása vagy a szerverek kímélése.
A podcastban érdekes anekdoták hangzanak el a Google múltjából, többek között a Backrub nevű korai keresőről is. Megvilágítják, mi a különbség az automatizált és a felhasználó által indított adatlekérdezések között, és hogyan reagálnak a crawler rendszerek azokra a jelekre, amelyeket a weboldalak adnak magukról (például a robots.txt használata).
Felvetődik a kérdés, mennyire változtak meg a webes robotok viselkedésmintái és technológiai háttere az elmúlt évtizedekben, valamint szóba kerülnek etikai és technikai problémák is, mint például a túlterhelés veszélye vagy a szabályok betartása. Rámutatnak arra is, hogy hasonló problémákkal más nagy webes cégek és keresők is szembesülnek.
A témát tovább árnyalja a különböző típusú internetes forgalom és az új AI-alapú adatgyűjtés pozitív és negatív hatásainak megvitatása. Elhangzik, milyen jelentős szerepet töltenek be a közös adatkészleteket előállító szolgáltatások, például a Common Crawl.